1. 스프링 카프카
- 카프카 클라이언트에서 사용하는 여러 가지 패턴을 미리 제공한다.
- 컨슈머를 멀티 스레드로 운영하기 위한 스레드 풀 로직은 스프링 카프카를 사용하면 concurrency 옵션 하나만 추가하면 어렵지 않게 구현할 수 있다.
- 스프링 카프카 라이브러리는 어드민, 컨슈머, 프로듀서, 스트림즈 기능을 제공한다.
1.1 스프링 카프카 프로듀서
- 스프링 카프카 프로듀서는 카프카 템플릿이라고 불리는 클래스를 사용하여 데이터를 전송할 수 있다.
- 카프카 템플릿은 프로듀서 팩토리(ProducerFactory) 클래스를 통해 생성할 수 있다.
- 카프카 템플릿을 사용하는 방법
- 기본 카프카 템플릿 사용
- 카프카 템플릿을 프로듀서 팩토리로 생성하는 방법
1.1.1 카프카 프로듀서 예제
- 스프링 카프카에서 프로듀서를 사용할 경우에는 필수 옵션이 없다.
- 옵션을 설정하지 않으면 bootstrap-server = localhost:9092, key-serializer, value-serializer = StringSerializer로 자동 설정되어 실행된다.
private static String TOPIC_NAME = "test";
private final KafkaTemplate<Integer, String> template;
public SpringProducerApplication(KafkaTemplate<Integer, String> template) {
this.template = template;
}
public static void main(String[] args) {
SpringApplication.run(SpringProducerApplication.class, args);
}
@Override
public void run(String... args) throws Exception {
for (int i = 0; i < 10; i++) {
template.send(TOPIC_NAME, "test " + i).addCallback(new KafkaSendCallback(){
@Override
public void onSuccess(Object result) {
System.out.println("success" + result.toString());
}
@Override
public void onFailure(KafkaProducerException ex) {
ex.printStackTrace();
}
});
}
System.exit(0);
}
1.2 스프링 카프카 컨슈머
- 타입은 레코드 리스너(MessageListener)와 배치 리스너(BatchMessageListener)가 있다.
- 레코드 리스너는 단 1개의 레코드를 처리한다.
- 배치 리스너는 한 번에 여러 개 레코드를 처리한다.
- 메뉴얼 커밋을 사용할 경우에는 Acknowledging이 붙은 리스너를 사용한다.
- KafkaConsumer 인스턴스에 직접 접근하여 컨트롤하고 싶다면 ConsumerAware가 붙은 리스너를 사용한다.
- 기존 카프카 클라이언트 라이브러리에서 컨슈머를 구현할 때 가장 어려운 부분이 커밋을 구현하는 것이다.
- 스프링 카프카에서는 사용자가 사용할만한 커밋의 종류를 미리 세분화하고 로직을 만들어놨다.(AckMode)
- 리스너를 생성하고 사용하는 방식
- 기본 리스너 컨테이너를 사용
- 컨테이너 팩토리를 사용하여 직접 리스너를 만드는 것
2. Spring Kafka Template
- 아래의 소스코드를 보면서 글을 읽으면 이해하기가 수월합니다 🙂
- README.md 파일의 How to run 을 보시면 간단하게 도커로 카프카 서버를 띄우고 Producer & Consumer 테스트를 해볼 수 있습니다.
https://github.com/harrisleesh/spring-kafka-template
2.1 의존성
implementation("org.springframework.boot:spring-boot-starter-web") - (1)
implementation("org.springframework.boot:spring-boot-starter-aop") - (2)
implementation("org.jetbrains.kotlinx:kotlinx-serialization-json:1.4.0") - (3)
implementation("org.springframework.kafka:spring-kafka") - (4)
- 스프링 MVC 를 위한 의존성
- 카프카 이벤트 생성 시 AOP를 적용하기 위해 추가
- 객체를 카프카로 전달할 때 직렬화하기 위한 의존성
- Kafka Client를 SpringFramework에서 편하게 사용할 수 있게 해주는 의존성
2.1.1 버전 관리
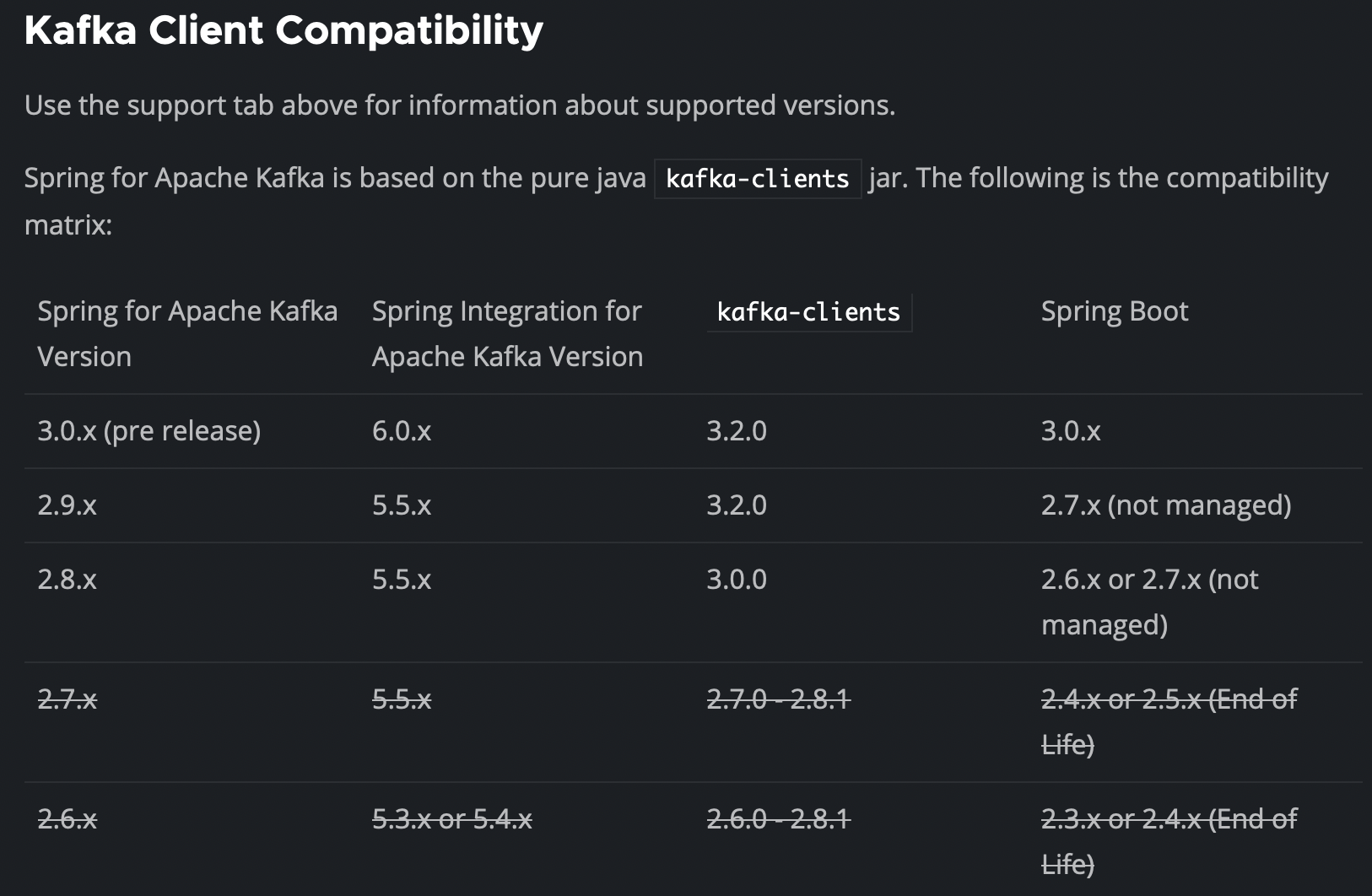
- 스프링 카프카 공식 레퍼런스에서 스프링 카프카의 버전에 해당하는 카프카 서버의 버전, 스프링 부트의 버전을 명시하고 있습니다.
- 사용하는 카프카 서버의 버전을 확인하고 이에 맞는 스프링 카프카의 버전을 사용해야 합니다.
2.2 환경파일
spring:
application:
name: spring-kafka
profiles:
active: local
---
spring.config.activate.on-profile:
- local
spring:
kafka:
consumer:
bootstrap-servers: 127.0.0.1:9093 #(1)
listener:
ack-mode: MANUAL_IMMEDIATE #(2)
type: single
producer:
bootstrap-servers: 127.0.0.1:9093 #(1)
acks: all
---
spring.config.activate.on-profile:
- dev
spring:
kafka:
consumer: #(3)
bootstrap-servers: b-1.kps*.q*zx.c2.kafka.ap-northeast-2.amazonaws.com:9092,b-2.kp*sk.q*x.c2.kafka.ap-northeast-2.amazonaws.com:9092
listener:
ack-mode: MANUAL_IMMEDIATE
type: single
producer:
bootstrap-servers: b-1.kp*k.q*x.c2.kafka.ap-northeast-2.amazonaws.com:9092,b-2.kp*msk.q*x.c2.kafka.ap-northeast-2.amazonaws.com:9092
acks: all- Profile을 local로 설정하면 로컬 kafka에 연동한다.
- 컨슈머 리스너의 ack-mode, type 등을 설정한다.
- Profile을 dev로 설정하면 aws msk에 연동한다.
2.3 docker-compose
version: "2"
services:
zookeeper:
image: docker.io/bitnami/zookeeper:3.8
ports:
- "2181:2181"
volumes:
- "zookeeper_data:/bitnami"
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
kafka:
image: docker.io/bitnami/kafka:3.2
ports:
- "9092:9092"
- "9093:9093"
volumes:
- "kafka_data:/bitnami"
environment:
- KAFKA_BROKER_ID=-1
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9092
- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CLIENT:PLAINTEXT,EXTERNAL:PLAINTEXT
- KAFKA_CFG_LISTENERS=CLIENT://:9092,EXTERNAL://:9093
- KAFKA_CFG_ADVERTISED_LISTENERS=CLIENT://kafka:9092,EXTERNAL://localhost:9093
- KAFKA_CFG_INTER_BROKER_LISTENER_NAME=CLIENT
depends_on:
- zookeeper
volumes:
zookeeper_data:
driver: local
kafka_data:
driver: local
- docker로 zookeeper와 kafka 서비스를 구성하여 실행한다. (docker-compose up)
2.4 예제 코드 기능
- /template으로 API GET 요청이 왔을 때
- TemplateService에서 반환하는 TemplateDTO에 대해서 template 토픽으로 KafkaEventProducing을 한다.
- ConsumerService는 생성된 레코드들을 consuming 해서 print 한다.
2.4.1 Producer
interface TemplateKafkaPort {
fun produce(templateDTO: TemplateDTO): ListenableFuture<SendResult<Int, String>>
}
@Component
internal class TemplateKafkaAdapter(
val kafkaTemplate: KafkaTemplate<Int, String>
) : TemplateKafkaPort {
private val TOPIC_NAME = "template"
override fun produce(templateDTO: TemplateDTO): ListenableFuture<SendResult<Int, String>> {
return TemplateEventDTO.from(templateDTO)
.run {
kafkaTemplate.send(TOPIC_NAME, Json.encodeToString(this))
}
}
}
- kafkaTemplate의 send 메서드를 이용해서 “template”이라는 토픽으로 TemplateEventDTO를 String으로 인코딩하여 보낸다.
- 인코딩하기 위해서는 해당 DTO 객체를 다음과 같이 Serializable로 선언해주어야 한다.
@Serializable
data class TemplateEventDTO(
val name: String,
val count: Int,
@Serializable(with = LocalDateTimeSerializer::class)
val createdAt: LocalDateTime?,
)
AOP
- 예제 코드에서는 카프카 이벤트 프로듀싱을 Annotation이 선언된 메서드에 Aspect를 적용하는 방식으로 구현했습니다.
@Target(AnnotationTarget.FUNCTION)
annotation class KafkaEventProducing
@Aspect
@Component
class TemplateKafkaAspect(val templateKafkaPort: TemplateKafkaPort) {
@Around("@annotation(kafkaEventProducing)") // (1)
fun produceEvent(joinPoint: ProceedingJoinPoint, kafkaEventProducing: KafkaEventProducing): Any? {
return joinPoint.proceed() // (2)
.also {
println("kafka event producing ${it.toString()}")
}
.apply { // (3)
if (this is TemplateDTO) templateKafkaPort.produce(this)
}
}
}
- kafkaEventProducing 이라는 어노테이션이 선언된 메서드를 특정한다.
- joinPoint.proceed() 메서드를 실행하면 어노테이션이 선언된 메서드를 실행하고 그 결과를 받아올 수 있다.
- 받아온 결과(templateDTO)를 templateKafkaPort.produce 메서드를 사용하여 카프카 이벤트를 생성한다.
@KafkaEventProducing // (4)
fun getTemplate() : TemplateDTO{
return TemplateDTO("seonghun", 99, LocalDateTime.now())
}
4. 다음과 같이 실제 비즈니스 코드에서는 어노테이션만 붙여주면 반환 DTO에 대해 카프카 이벤트를 생성할 수 있다.
2.4.2 Consumer
class ConsumerService {
@KafkaListener(topics = ["template"], // (1)
groupId = "test-group-00" //(2)
)
fun recordListener(record: ConsumerRecord<String?, String?>) { // (3)
println(record.toString())
}
@KafkaListener(topics = ["template"], groupId = "test-group-01")
fun singleTopicListener(messageValue: String?) { // (4)
println(messageValue)
}
@KafkaListener(
topics = ["template"],
groupId = "test-group-02",
properties = ["max.poll.interval.ms:60000", "auto.offset.reset:earliest"]
)
fun singleTopicWithPropertiesListener(messageValue: String?) {
println(messageValue)
}
@KafkaListener(topics = ["template"], groupId = "test-group-03", concurrency = "3")
fun concurrentTopicListener(messageValue: String?) {
println(messageValue)
}
@KafkaListener(
topicPartitions = [TopicPartition(
topic = "template",
partitions = ["0"]
)],
groupId = "test-group-04"
)
fun listenSpecificPartition(record: ConsumerRecord<String?, String?>) {
println(record.toString())
}
}
- 컨슈머 서비스는 spring-kafka 라이브러리에서 제공하는 간단한 어노테이션으로 record를 가져올 수 있다.
- 가져올 토픽 이름을 지정한다.
- consumer-group-id 를 지정한다. (없으면 자동으로 생성해준다.)
- ConsumerRecord를 받아서 레코드 값과 함께 메타 데이터를 확인할 수 있다.
- messageValue만을 받을 수 있다.
Reference
'Infra' 카테고리의 다른 글
| 카프카 기본 개념 정리 (0) | 2022.08.30 |
|---|
